I would like to give credit to the original source of this command, but I just couldn't find it. It was some of those "shell one-liners" you see on hacker news five times a day, except I didn't know half of them. The most interesting was a semi-cryptic command line with a pretentious comment besides it:
# calculates pi the unix way
I remember as if it was today how puzzled I was by that line. As I said, I didn't know much of the incantations on that list, but this was by far the most magical. The line goes like this:
$ seq -f '4/%g' 1 2 9999 | paste -sd-+ | bc -l
If you like a challenge (as I do), try to figure it out by yourself. A shell and the man pages are your best friends.
seq
If shell (or python) wasn't your first programming language, you were probably surprised by the way loops are done. It usually goes like this:
$ for x in 1 2 3 4 5; do echo "$x"; done
1
2
3
4
5
If you have a little experience with shell, you probably learned there is a more idiomatic way of doing this using the seq command and some shell voodoo:
$ for x in $(seq 1 5); do echo "$x"; done
And if you were truly initiated on the dark arts of bash programming, you probably know this is functionally equivalent to this:
$ for x in {1..5}; do echo "$x"; done
I won't explain how shell command substitution works, suffice to say seq is a nice utility to generate sequences (get it?) of numbers. From the first lines of the man page:
$ man seq | grep -A 3 SYNOPSIS
SYNOPSIS
seq [OPTION]... LAST
seq [OPTION]... FIRST LAST
seq [OPTION]... FIRST INCREMENT LAST
So the main part of the first command on the pipe is no magic: we are generating numbers from 1 to 9999 with a step of 2:
$ echo $(seq 1 2 9999 | head -5)
1 3 5 7 9
There is a useful option to this command to control how the value is output:
$ seq -f '%02g' 1 3 10
01
04
07
10
Programmers familiar with c will recognize the printf format string. Moving down the pipe...
paste
There are some commands that do something so simple they seem almost useless:
$ whatis -l paste
paste (1) - merge lines of files
paste (1p) - merge corresponding or subsequent lines of files
Nothing really interesting here, right?
$ paste <(seq 1 3) <(seq 4 6)
1 4
2 5
3 6
$ seq 1 6 | paste - -
1 2
3 4
5 6
Well, that is interesting. What if we play with the other options?
$ paste -sd, <(seq 1 3) <(seq 4 6)
1,2,3
4,5,6
$ seq 1 6 | paste -sd,
1,2,3,4,5,6
This simple command is starting to show complex behavior. Maybe there is something interesting in those old unix books after all... Wait:
$ seq 1 6 | paste -sd+
1+2+3+4+5+6
Nice, a mathematical expression. If only we had some way of interpreting it...
bc
There are people who say: the python/ruby interpreter is my calculator. To that I say: screw that!
$ bc -ql
1 + 2 + 3
6
10 / 12
.83333333333333333333
scale = 80
10 / 12
.8333333333333333333333333333333333333333333333333333333333333333333\
3333333333333
Do you see that `\` character? It's almost as if it was meant to be used on a shell...
$ seq 1 6 | paste -sd+ | bc -l
21
Interlude: Gregory-Leibniz
There are many ways of calculating π. You can find many of them on its wikipedia page. One of them is named after two mathematicians, James Gregory and Gottfried Leibniz, goes like this (again from wikipedia):

This is an infinite series with a simple pattern, which I'm sure you can identify (you weren't sleeping on those calculus classes, were you?). Just in case you can't (and because it is a pretty equation), here it is:
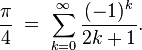
Back in unix-land
So here is the challenge: how can we generate and evaluate the terms of this series? Generating each term, without the sign, can be done easily with seq and a format string:
$ seq -f '1/%g' 1 2 9
1/1
1/3
1/5
1/7
1/9
Remember our useful-where-you-never-imagined friend paste?
$ seq -f '1/%g' 1 2 9 | paste -sd-+
1/1-1/3+1/5-1/7+1/9
This may take some time to understand, it's ok. Read those man pages! But once you understand, the only thing left is to evaluate the expression:
$ seq -f '1/%g' 1 2 9 | paste -sd-+ | bc -l
.83492063492063492064
Hmm, not much π-like, is it? Right, this is π/4. Ok, we can rearrange the terms a bit to fit our tools (that is the essential hacker skill). Lets move the denominator on the right side to the numerator on the left.
$ seq -f '4/%g' 1 2 9 | paste -sd-+ | bc -l
3.33968253968253968254
That's more like it! As any infinite series approximation, we can increase the number of terms to increase accuracy:
$ seq -f '4/%g' 1 2 9999 | paste -sd-+ | bc -l
3.14139265359179323814
Now just for the heck of it:
$ seq -f '4/%g' 1 2 999999 | paste -sd-+ | bc -l
3.14159065358979323855
And there you have it. Enjoy your unix π.
